A couple of years ago, Colin Kelly and I got pulled into an interesting problem at Invoca. We had a call-tracking API — the Ring Pool API — that hands out unique phone numbers tied to marketing context so calls can be attributed back to the campaign that drove them. It worked fine on Rails: about 5 requests per second per connection, 350ms p90.
Then a client showed up asking for 1,000+ requests per second per connection, 40 numbers per request, and p90 under 200ms. Roughly an 8,000x throughput bump for a single customer.
We wanted to stay in Ruby. Here's how we did it.
The two obstacles
The GIL. On MRI, one Ruby process gets one core. You can't write truly parallel Ruby here — you can only run multiple cooperative processes. So we sharded the API across cores.
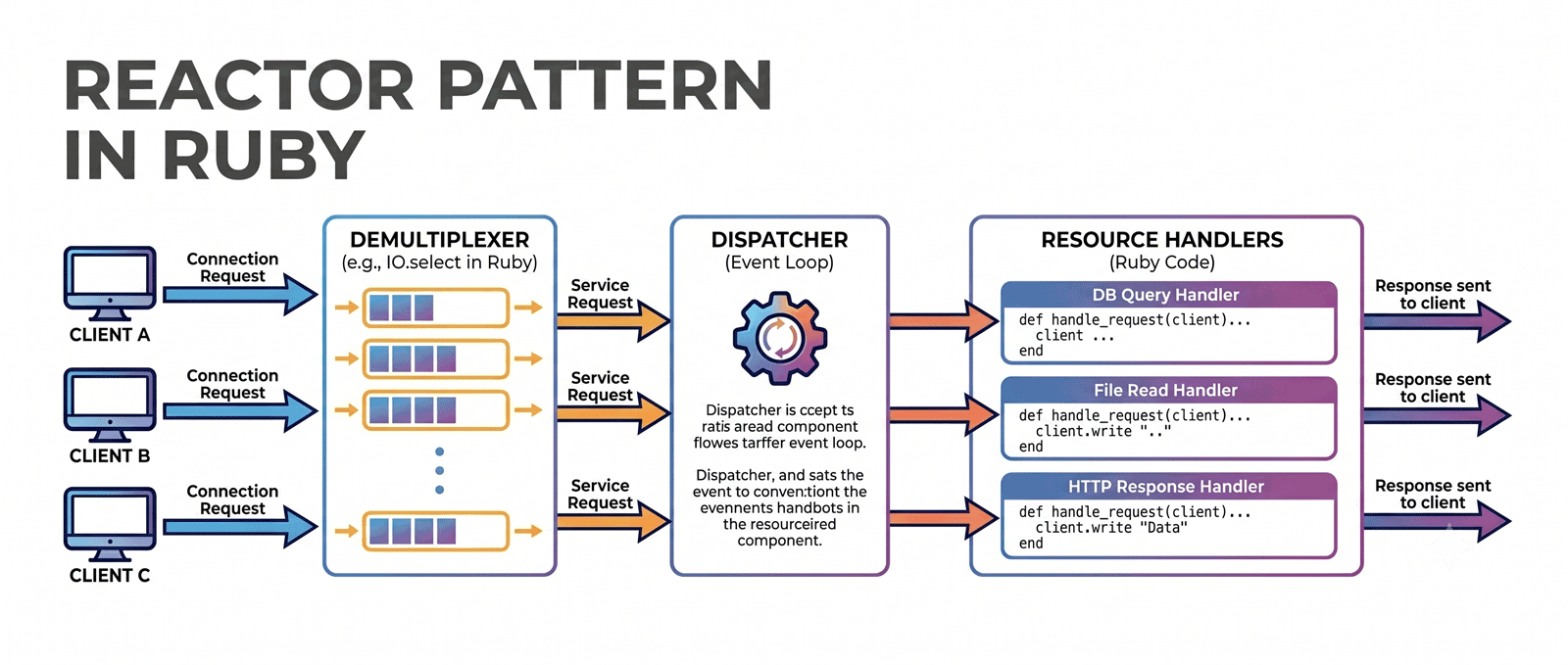
C10K. We didn't want to write heavily threaded Ruby and hope we got the locking right. The reactor pattern sidesteps the problem: when code would block on I/O, you queue a callback and move on; when the I/O completes, the callback runs. Node does this. Twisted does this. In Ruby, EventMachine does this.
Goliath, EventMachine, and synchrony
Raw EventMachine means writing callbacks and errbacks for every blocking call, and they tend to be 80% duplicated. It gets brittle fast.
em-synchrony fixes this by using fibers to make async code look linear. When a method blocks, the fiber's state gets parked and the reactor moves on; when the I/O completes, the fiber resumes. Same pattern as Go's goroutines. You write ordinary-looking Ruby and the machinery handles the rest.
Goliath is a Rack-compatible web server built on all of this. Each request runs in its own fiber. I/O transparently suspends and resumes. You write a response method and return a standard Rack triple.
In a toy benchmark, the evented version outran a threaded equivalent by more than 2x — no mutexes, no async interruption. In a real app, expect closer to 1.5x, but the density advantage is real.
What actually mattered in the code
A few design choices did most of the work:
- Thin models, autoloader off. \ ActiveRecord's autoloader happily drags half your app into memory through association chains. We turned it off on the API server and required only what we needed. Validations and callbacks are expensive too — keep models lean.
- Exception handling across fiber boundaries. \
We wrote a small gem (exceptional-synchrony) to tunnel exceptions across callbacks so we could use normal
raise/rescueinstead of duplicating cleanup in errbacks. A nice side effect: the code became unit-testable without booting the reactor. - Catch everything at the top. \
An uncaught exception inside a fiber kills the process. We wrap the top-level EventMachine methods and rescue
Exception— which is normally a smell, but appropriate at the true top of an always-running server. We learned this the hard way from aFile.openpermissions error that kept taking down shards. - Immutable value classes over hashes.\ Most of the codebase ended up as small POROs with design-by-contract in the initializer, no writers, and their own serialization. Hashes almost never serialize to exactly what you want once internal bookkeeping diverges from the external contract. Immutability also matters more than you'd think in fiber-land — data can change across yield points, and "don't mutate" is the simplest guarantee.
- Modified singletons.\ Real initializers that take dependencies, plus class methods for a conventional default instance. A month after shipping, we needed two credentials files at once — trivial with this pattern, impossible with a classic singleton.
Architecture
- HTTP/1.1 keep-alive between shards to avoid paying 20ms per TCP handshake.
- Unix domain sockets for shards on the same box.
- HAProxy on every API server, because ELB only forwards to one port per server and we needed to round-robin across shard processes.
- No watchdog. Our first failure-handling design had a Watchdog process monitoring shards. But — who watches the watchdog. Instead we taught every shard the overflow number for every ring pool. If a shard is slow, the caller just hands back an overflow directly. We also rate-limit cross-shard calls: when a shard looks slow, we stop hitting it and gradually ease back in as it recovers.
The numbers
JMeter against our EC2 setup:
- 3 JMeter instances: 93ms median, 124ms p90, 400 req/s
- 4 instances: 102ms median, 144ms p90, 1,700 req/s
- 5 instances: ~2,000 req/s — and at that point JMeter was the bottleneck, not us
Comfortably past the SLA. AWS VPCs on the private backbone would've bought another 10–15ms per round trip.
There are about 5.5 billion phone numbers in North America. At this rate, we could hand out every one of them in under 12 hours.
If you're thinking about trying this
Goliath + EventMachine + em-synchrony is a genuinely good stack for high-throughput Ruby APIs. Shard across cores, keep your models thin, handle exceptions at the top of every fiber, and prefer plain old Ruby objects to hashes. I'd love to see an evented option ship with Rails itself someday — EventMachine was on the Rails 5 roadmap, and pairing it with synchrony would reclaim some of the density story Node has owned for a while.
See my talk on Youtube: https://www.youtube.com/watch?v=U8An88L5nBk